What is SQL
SQL (Structured Query Language) is the de-facto standard language to query and manipulate information stored in relational databases (as well as some non-relational ones). It has a declarative syntax that allows its users to describe what they want to do, leaving it to the Relational Database Management System (RDBMS, the software managing your database) to decide how to do it in the most efficient way.
Even though it was originally developed for and used primarily in software engineering, SQL is nowadays extensively used for data analysis in a wide variety of market sectors, making it a core skill for many job roles.
Reference: Why you need to learn SQL
Outline
In this series of articles, you will learn what SQL is about and how you can use it to retrieve data from a database: each article (except this one, which only serves an introduction) will contain explanations about the syntax, examples, and a link to a PushMetrics notebook that you can use to practice what you have learned.
This course assumes no prior knowledge of SQL and doesn’t require any software installation (thanks to PushMetrics): you’ll first learn the basics of the SQL syntax, such as filtering, sorting, and grouping data, practicing them on a database containing a single table; later on, you will learn about joining data and you will start using a revised version of that same database, containing multiple tables; finally, you will have a sneak peek at windowing functions and how they can be used for data analysis.
Disclaimer: The databases you will use to practice, have been kept as simple as possible for educational purposes. Their design may not always follow best practices.
We’d like to say thanks to Federico Ragona who wrote and developed this course materials
SQL and Spreadsheets
You might be wondering why one would need SQL at all, since spreadsheets offer almost the same features. This is a fair question, whose answer is, in fact “it depends”. Some of the most common spreadsheet features are very useful for investigations: for example, the fact that they accept unstructured data means that we can dump any sort of data into a spreadsheet and then start exploring and refining it according to our needs; moreover, the fact that they have built-in visualization tools is useful to make sense of the underlying data.
The problem with spreadsheets is that they lose performance as the size of your dataset grows over a few thousand rows (*). Moreover, the fact that they accept unstructured data can bite us back, because we have no guarantees over the data quality and what kind of data we can expect.
SQL, on the other hand, is able to manage huge datasets (billions of rows) and requires us to describe the structure of our data upfront: while requiring more work at the beginning, this guarantees us that invalid records cannot simply be inserted into it, thus removing entire categories of errors.
(*) The exact limit depends on the software you are using, your computer’s specs, and how heavily your spreadsheet makes use of functions and other data analysis features.
References:
Relational Model
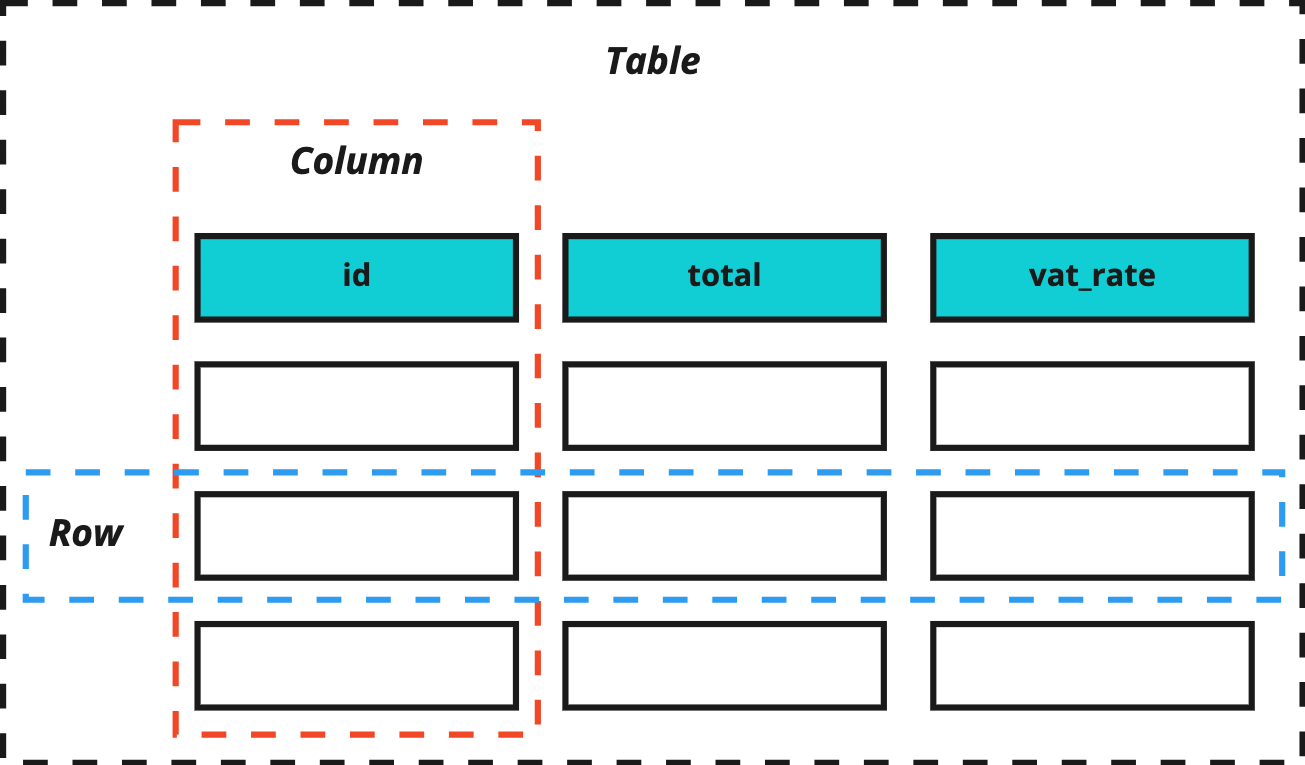
SQL was developed to interact with databases designed around the relational model. In this model, information is organized in relations (called tables in RDBMs): a relation is a set of tuples (= rows) that share the same set of attributes (= columns).
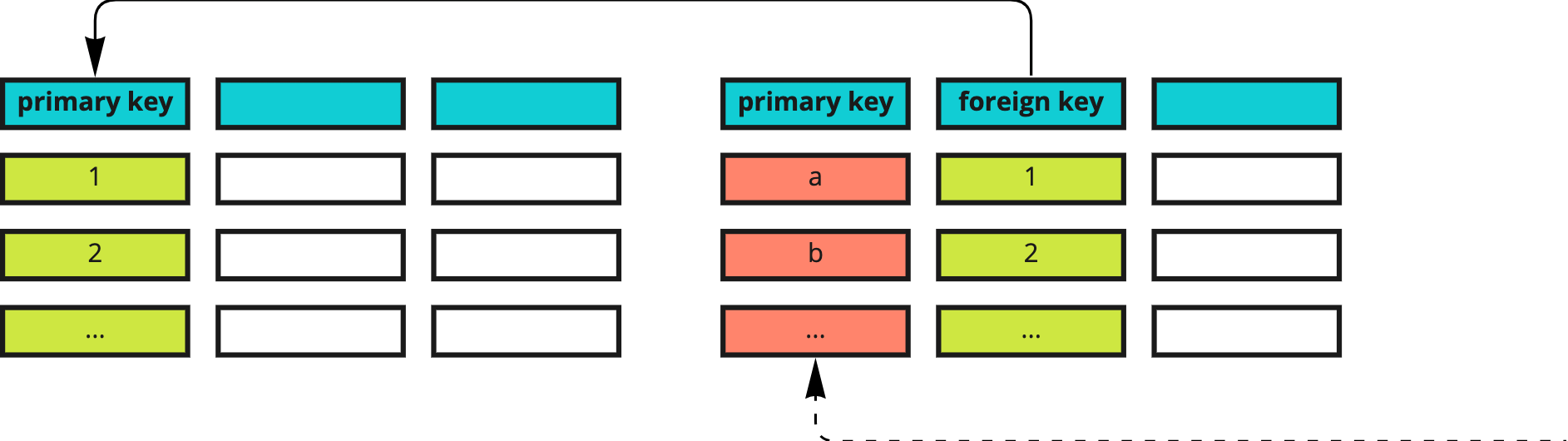
Each table contains at least one column that uniquely identifies each row, called the primary key. A table may also define a foreign key, a column referencing the primary key of another table which can be used to guarantee data integrity and join the tables' contents in queries. We’ll discuss this more in depth in an article later on, when we talk about joining data.
Reference: Understanding Relational Databases
Basic data types
Each column in a table is described by a name and a data type, which restricts the range of values it accepts: for example, the integer data type allows whole numbers (e.g. -231, 0, 42) but not numbers with a fractional component or non-numeric values like text, date, … This is an important property, because it gives us guarantees about the content of our tables: a value that doesn’t belong to the column’s data type simply cannot be inserted into it.
These are the most common data types provided by SQL:
| Data type | Description | Examples |
|---|---|---|
| integer | Accepts whole numbers | -231 0 42 |
| float / double / decimal | Accept numbers with a fractional component; the precision with which they are able to represent numbers varies according to the chosen type | -10.5 0 0.333 25.001 |
| char, text, varchar | Accepts text of fixed (`char`) or variable (`text`, `varchar`) length | 'Hello world!' 'SQL is a standard since the 1980s' |
| date, datetime, time, timestamp | Accepts date and/or time information | ‘2022-06-22 18:30:00 +02:00’ ‘2022-06-22’ ‘18:30:00’ |
| boolean | Accepts two values: true and false | true false |
| large object | Accept binary/character large objects (called BLOB and CLOB, respectively) | |
| document | Accepts XML or JSON documents |
Each data type comes with its own set of operations, which can be used to manipulate their values (see link below for some examples). In addition to the basic data types, DBMSs may provide their own custom ones for more specific use cases.
Please note that some data types may (and will, typically) have different names according to the DBMS you use, so you will need to check their documentation.
Reference: SQL Data Types